What is a minimal load/stress test plan for a new service or application? A minimal plan covers two scenarios:
- Scalability Test
- Stability Test
1. Scalability
Vertical scalability is a measure of how effectively an application can handle increasing amounts of load on a single server. Ideally, the application can handle increasing amounts of load without significant degradation in response time until reaching some server resource limit such as CPU limits or network adaptor bandwidth limits. The results of a scalability test can be presented in a chart such as the following:

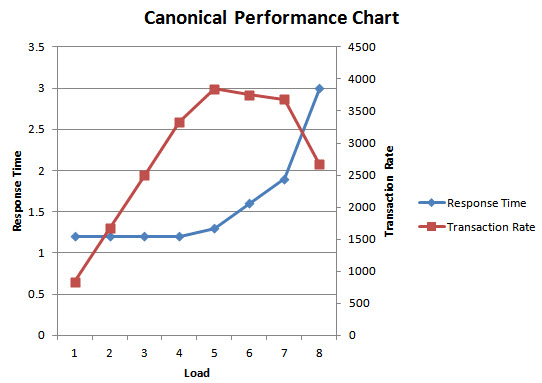
The chart shows, for each of 8 tested load levels, the response time and the transaction rate of the application. In this case each load level is a number of concurrent requests in increments of one. In other cases other increments may be appropriate (such as increments of 10) and other measures of load may be appropriate (message size, etc.). Load should be driven high enough that throughput levels off. Response time will ideally remain flat as load increases, eventually turning a knee or corner and heading upwards as capacity is reached. In this case, the application scales nearly perfectly up to 5 concurrent requests, then begins to degrade, with peak throughput around 4,500 queries per second.
The scalability chart provides a large amount of information that can be used for capacity planning, production configuration, etc. It shows what response times are under typical loads. It shows the throughput capacity of a single server running the application, and it shows the behavior as capacity is exceeded.
As part of a scalability test, metrics showing server resource usage at each load level should be captured, such as CPU usage, network usage, disk usage, and memory usage. Logs and errors should be captured. Similar information should be captured on any downstream systems involved in the test if any, such as databases or services.
Part of the test analysis should involve bottleneck analysis, which is analyzing and determining what is limiting the capacity of the application, what is limiting it to 4,500 queries per second. This could be server resource usage (hitting CPU, network or disk limits), it could be an increase in response time of a downstream database or server as load increases, it could be contention within the application such as thread blocking or error paths hit at high loads, etc.
An appropriate environment for a scalability test would involve two servers, one for the application and one to act as the client driving the load:
Server resource usage on the load generator should be monitored as well to verify that it is not the bottleneck.
This type of vertical scalability test does not guarantee that the application will scale out horizontally for two reasons: (1) there may be downstream systems such as databases that become bottlenecks at higher loads, and (2) load balancing or clustering systems may not scale as expected. More extended testing beyond a minimal plan would have to cover these factors as well.
For the vertical scalability test, it is important to drive the application up to peak capacity, regardless of what expected load may be. Usage may be different than expected, spikes in load may occur, business might grow, etc. Some performance or stability problems only manifest themselves at higher loads, and it is important to identify these even if production load is expected to be much lower.
2. Stability
The second part of the minimal load test plan is the stability test. To verify stability, a high load should be run against the application for an extended period of time, at a minimum 24 hours and ideally for days or weeks. A high load can be determined from the results of the scalability test, just below peak capacity, just below the point at which response time takes a turn for the worse. In the example above, a load of 5 concurrent requests could be used, assuming those are the final results following resolution of performance bottlenecks.
During the run, server resource usage should be captured and monitored, and error logs monitored, as with the scalability test. Trends should be monitored closely. Does response time degrade over time? That indicates a resource leak. Does CPU usage increase over time? That indicates a design or implementation error. Does memory leak? Do errors begin to occur at some point or occur in some pattern? Does the application eventually crash?
Beyond the Minimal Plan
Beyond the minimal plan, other tests are required to ensure the application is completely performant and stable. These will be covered later (
http://sub-second.blogspot.com/2011/11/extending-load-test-plan.html) and include:
- Performance regression
- Horizontal scalability
- Fault tolerance