
The answer is that you test it at different levels of granularity, typically three levels. One, obvious level is the service. Another level is end to end. The third level is the module level, the low-level building blocks making up the service.
One necessary precondition to adequate performance testing services is proper instrumentation providing key performance metrics. Response times, transaction rates, and and success/failure counts must be available for all service entry points and downstream calls. This allows response time contributions to be allocated accurately to the proper services and allows fast performance problem debugging.
The three layers of SOA performance testing share the following in common.
- Scalability Testing
- What is capacity?
- What bottleneck is limiting capacity?
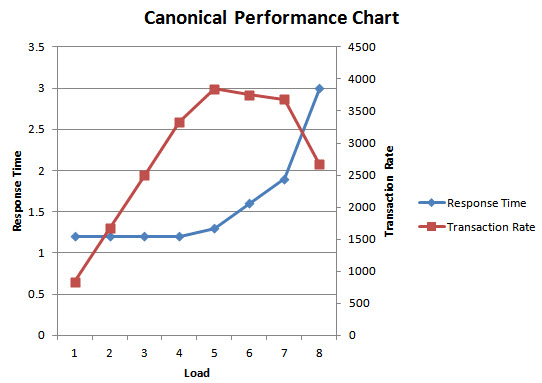
- What is response time at various loads?
- What is the canonical performance chart?
- Stability Testing
- Is the application stable?
- Is the application fault tolerant?
- Performance Regression Testing
- Does performance degrade from build to build?
- Does server resource usage increase from build to build?
- Metrics on server resource usage
- CPU
- Memory
- Network
- Disk
Module level SOA performance testing is done as follows:
- Test key functional code paths at module level
- Use multi-threaded, concurrent execution
- Run within unit test framework
- Run within continuous integration framework
- Run frequently, each check-in, build, or version
Service level SOA performance test is done as follows:
- Test through public entry point
- Isolate service under test from other services
- Use spoofing or stubbing of backend services, mimicking their response time behavior
- Determine response time and availability service level agreements (SLAs) based on test results
- Thoroughly test the clustering or load balancing mechanism used to scale the service out horizontally.
End to end level SOA performance test is done as follows:
- Test public entry point into the application
- Verify that bottlenecks hit are consistent with capacity of individual services discovered in service-level testing.
- Verify fault tolerance of unavailable downstream services
An additional layer is infrastructure testing. This could include messaging infrastructure, caching infrastructure, storage infrastructure, database infrastructure, etc. Key infrastructure should be directly tested for scalability and stability in some cases to ensure that it behaves as expected and scales as expected.
SOA performance testing can be summarized in the following conceptual chart:





